
题外话:
大多数暴力破解导致超时是因为:重复计算
优化点在于如何高效利用已经计算的结果
看了一眼文章介绍,发现是讲贪心
贪心算法没有“远见”,它不会像动态规划那样考虑全局所有可能性。它只关注当前这一刻的状态。
如果每一步都走得好(局部最优),那么把这些步骤连起来,最终的结果应该也是最好的(全局最优)。
一、买卖股票的最佳时机
简单
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。提示:
1 <= prices.length <= 10^50 <= prices[i] <= 10^4
1.1 暴力起手(明显超时)
采用双重循环,第一重循环确定买入价格,第二重循环确定卖出价格,不断比较当前利润是否为最大
/**
* 121. 买卖股票的最佳时机(暴力)
*
* @param prices 价格数组
* @return 最大利润
*/
public int maxProfit(int[] prices) {
int maxprofit = 0;
for (int i = 0; i < prices.length - 1; i++) {
for (int j = i + 1; j < prices.length; j++) {
int profit = prices[j] - prices[i];
if (profit > maxprofit) {
maxprofit = profit;
}
}
}
return maxprofit;
}1.2 思想优化
要想获得最大利润,体育老师讲过,用最大值 - 最小值
对于买卖股票,要先买才能卖
- 所以在遍历数组的时候,i 左侧买入,i 时刻卖出
- i 左侧记录最低买入价格
min - i 时刻不断试着卖出,比较最大利润
/**
* 121. 买卖股票的最佳时机
*
* @param prices 价格数组
* @return 最大利润
*/
public int maxProfit(int[] prices) {
int min = Integer.MAX_VALUE;
int profit = 0;
for (int price : prices) {
min = Math.min(price, min);
profit = Math.max(price - min, profit);
}
return profit;
}执行用时1ms,击败100.00%,复杂度O(N)
消耗内存92.55MB,击败23.95%,复杂度O(1)
二、跳跃游戏
中等
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。提示:
1 <= nums.length <= 10^40 <= nums[i] <= 10^5
2.1 状态推导
在每个位置,除了0,肯定可以前进
定义上一个可到达的位置 site
从终点往回走,如果当前节点的步长 > site - i,即该节点可达,记录为新的节点
如果能回到一开始的节点,说明正序可达
/**
* 55. 跳跃游戏
*
* @param nums 提供的数组
* @return 是否能到达最后一个位置
*/
public boolean canJump(int[] nums) {
int site = nums.length - 1;
for (int i = nums.length - 2; i >= 0; i--) {
if (nums[i] == 0) continue;
if (site - i <= nums[i]) {
site = i;
}
}
return site == 0;
}执行用时2ms,击败91.79%,复杂度O(N)
消耗内存47.22MB,击败6.59%,复杂度O(1)
三、跳跃游戏 II
中等
给定一个长度为 n 的 0 索引整数数组 nums。初始位置在下标 0。
每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在索引 i 处,你可以跳转到任意 (i + j) 处:
0 <= j <= nums[i]且i + j < n
返回到达 n - 1 的最小跳跃次数。测试用例保证可以到达 n - 1。
示例1:
输入: nums = [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。示例 2:
输入: nums = [2,3,0,1,4]
输出: 2提示:
1 <= nums.length <= 10^40 <= nums[i] <= 1000- 题目保证可以到达
n - 1
3.1 递归解法
distance: 记录在当前搜索范围内能够到达的最远距离
site: 记录在当前搜索范围内能够到达最远距离的起跳位置
res: 跳跃次数
在当前范围内,提前搜索下一个范围中,可以到达的最远距离
distance = i + nums[i]将 i 点所在位置,视为新的起点,继续搜索下一个范围
如果当前囊括的范围已超出数组最大长度,直接返回, res++ 视为完成最后一次跳跃
class Solution {
private int distance;
private int site;
private int res;
/**
* 45. 跳跃游戏 II(递归)
* @param nums 提供的数组
* @return 最少跳跃次数
*/
public int jump(int[] nums) {
if (nums[0] == 0 || nums.length == 1) return 0;
distance = site = res = 0;
helper(nums, 0, nums[0]);
return res;
}
private void helper(int[] nums, int start, int end) {
if (end >= nums.length - 1) {
res++;
return;
}
for (int i = start; i <= end; i++) {
if (i + nums[i] > distance) {
site = i;
distance = i + nums[i];
}
}
res++;
helper(nums, end, distance);
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存46.41MB,击败30.72%,复杂度O(1)
3.2 迭代解法
以下均引用自灵茶山艾府_45. 跳跃游戏 II 题解↗
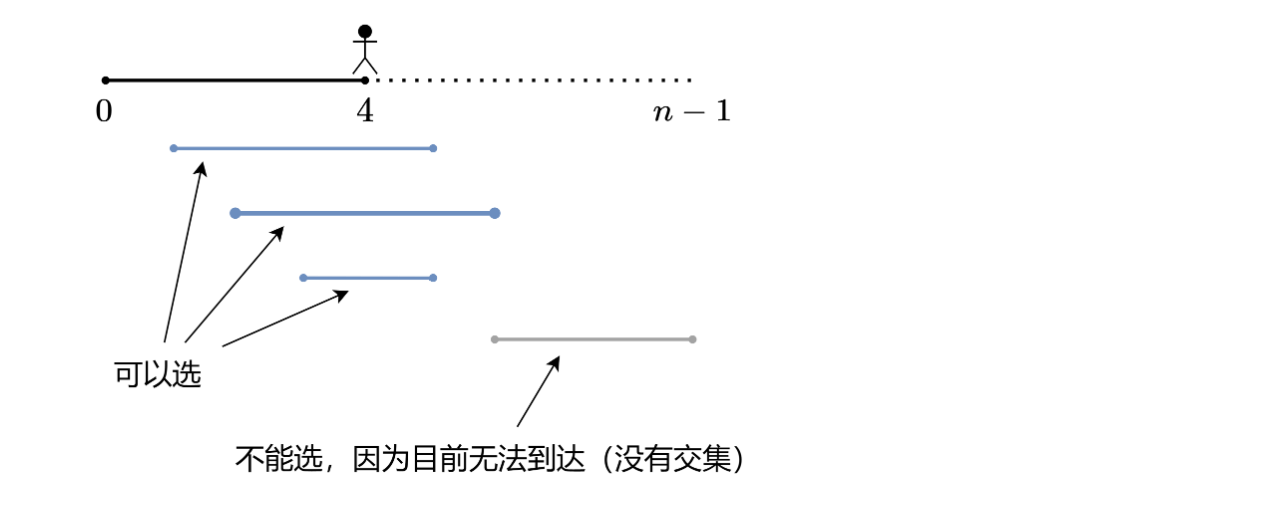
- 想象有一条河,
0和n - 1分别是河的两岸。一开始,你在0,要到n - 1- 把区间
[i, i + nums[i]]视作一座桥。一开始只能建一座桥,也就是[0, nums[0]]。- 比如建造了一座从0到4的桥。下一座桥要选哪个呢?
- 在可以选的桥中,选择右端点最大的桥。它会让你走得更远。
- 重复该过程,在能到达终点时退出循环。修建的桥的数量就是答案。
⚠注意:不是在无路可走的那个位置造桥,而是当发现无路可走的时候,时光倒流到能跳到最远点的那个位置造桥。换句话说,在无路可走之前,我们只是在默默地收集信息。当发现无路可走的时候,才从收集到的信息中,选择最远点造桥。所建造的这座桥的左端点(起跳位置)可能在我们当前走的这座桥的中间。
❓为什么代码只需要遍历到 n−2
- 代码中的 for 循环计算的是在到达终点之前需要造多少座桥。n−1 已经是终点了,不需要造桥。或者说,遍历到 n−2 时,要么已经可以到达终点,要么需要造最后一座桥。
❓如果题目没有保证一定能到达 n−1,代码要怎么改
class Solution {
public int jump(int[] nums) {
int ans = 0;
int curRight = 0; // 已建造的桥的右端点
int nextRight = 0; // 下一座桥的右端点的最大值
for (int i = 0; i < nums.length - 1; i++) {
// 遍历的过程中,记录下一座桥的最远点
nextRight = Math.max(nextRight, i + nums[i]);
if (i == curRight) { // 无路可走,必须建桥
curRight = nextRight; // 建桥后,最远可以到达 next_right
ans++;
}
}
return ans;
}
}执行用时1ms,击败99.59%,复杂度O(N)
消耗内存46.67MB,击败5.01%,复杂度O(1)
四、划分字母区间
中等
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。例如,字符串 "ababcc" 能够被分为 ["abab", "cc"],但类似 ["aba", "bcc"] 或 ["ab", "ab", "cc"] 的划分是非法的。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = "ababcbacadefegdehijhklij"
输出:[9,7,8]
解释:
划分结果为 "ababcbaca"、"defegde"、"hijhklij" 。
每个字母最多出现在一个片段中。
像 "ababcbacadefegde", "hijhklij" 这样的划分是错误的,因为划分的片段数较少。 示例 2:
输入:s = "eccbbbbdec"
输出:[10]提示:
1 <= s.length <= 500s仅由小写英文字母组成
4.1 合并区间
本质上是合并区间的一种:普通数组 56. 合并区间
- 我们并不关心每个字母所有出现的位置,只需要知道该字母的起始位置即可
- 先遍历一遍字符串,记录每个字母最后出现的位置
last[str[i] - 'a'] - 再次遍历字符串,进行区间合并,先更新当前区间的结束位置,再判断:
- 当前已到达结束位置,把结果添加进
ans - 未到达,继续遍历
/**
* 763. 划分字母区间
*
* @param s 提供的字符串
* @return 划分后的区间长度数组
*/
public List<Integer> partitionLabels(String s) {
char[] str = s.toCharArray();
int[] last = new int[26];
for (int i = 0; i < str.length; i++) {
last[str[i] - 'a'] = i;
}
List<Integer> ans = new ArrayList<>();
int start = 0;
int end = 0;
for (int i = 0; i < str.length; i++) {
end = Math.max(end, last[str[i] - 'a']);
if (i == end) {
ans.add(end - start + 1);
start = i + 1;
}
}
return ans;
}执行用时2ms,击败99.50%,复杂度O(N)
消耗内存43.04MB,击败11.02%,复杂度O(1)