
零、前言
0.1 记忆化
题外话:
大多数暴力破解导致超时是因为:重复计算
优化点在于如何高效利用已经计算的结果
记忆化 ≈ 递归版的动态规划
| 方面 | 记忆化(Memoization) | 动态规划(DP) |
|---|---|---|
| 方向 | 自顶向下(Top-down) | 自底向上(Bottom-up) |
| 调用方式 | 递归调用 | 迭代循环 |
| 计算顺序 | 按需计算,可能不全 | 计算所有子问题 |
| 空间使用 | 栈空间+存储空间 | 存储空间 |
| 初始化 | 不需要预先初始化 | 需要初始化基础情况 |
0.2 子问题模型
子问题确定:选或不选、尝试以每个位置作为起点(或终点)
思考后续最优是否取决于“具体选了哪个前驱”。
如果需要记住“哪个”前驱,就用“枚举选哪个”;如果只需知道“选/不选”以及一个小的局部状态,就用“选或不选”。
- 选或不选(二叉决策)适用:
- 每个元素的选择只影响一个小而固定的局部状态(如容量、是否选了前一个),不需要记住“具体哪个前驱”。
- 典型:0-1背包 完全背包【基础算法精讲 18】_哔哩哔哩_bilibili↗、打家劫舍(状态:i 是否选、用
dp[i]与dp[i-1]或dp[i-2]转移)、零钱兑换(按金额/硬币迭代) - 状态维度小、转移不需要在多个前驱中“挑最优”。
- 枚举选哪个(多前驱转移)适用:
- 以某位置 j 结尾的最优需要在“多个候选前驱 i”中取最大/最优(必须知道选的是哪个 i)。
- 典型:最长递增子序列
- 若强行用“选或不选”,通常要把“上一个选的下标/值”进状态,即
dp[pos][prevIndex]或dp[pos][prevValue],状态量涨到 O(n^2) 或更大,时间/空间都变差。
模板dp套路
确定dp维数
定义dp数组
基本状态转移方程
初始状态
0.3 选或不选的思想
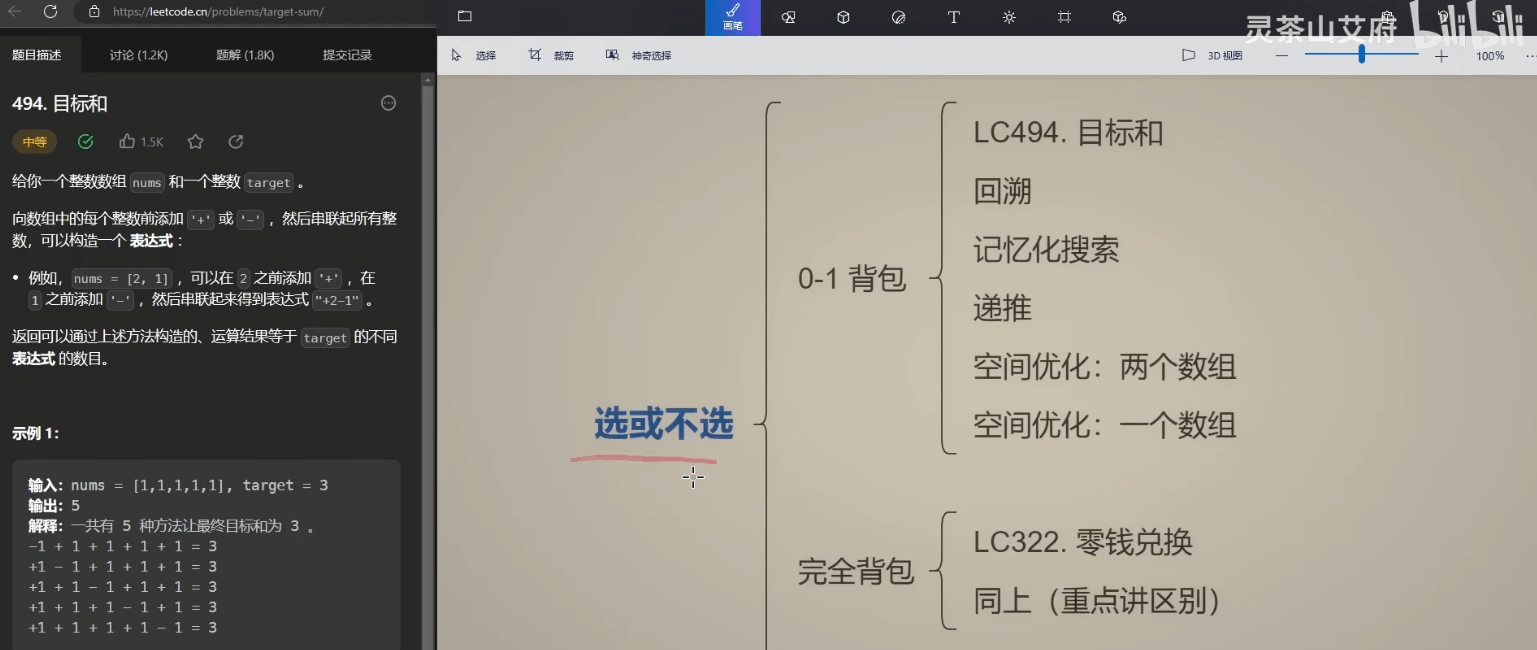
对于背包来说,空间优化写法,0-1 背包倒序迭代,完全背包正序迭代。0-1背包必须倒序的原因是因为, 如果是正序的话, 后面的遍历会用到前面的遍历的结果, 即同一个物体重复使用, 所以就要倒序; 完全背包则反过来, 因为必须要求可以重复使用, 故正序
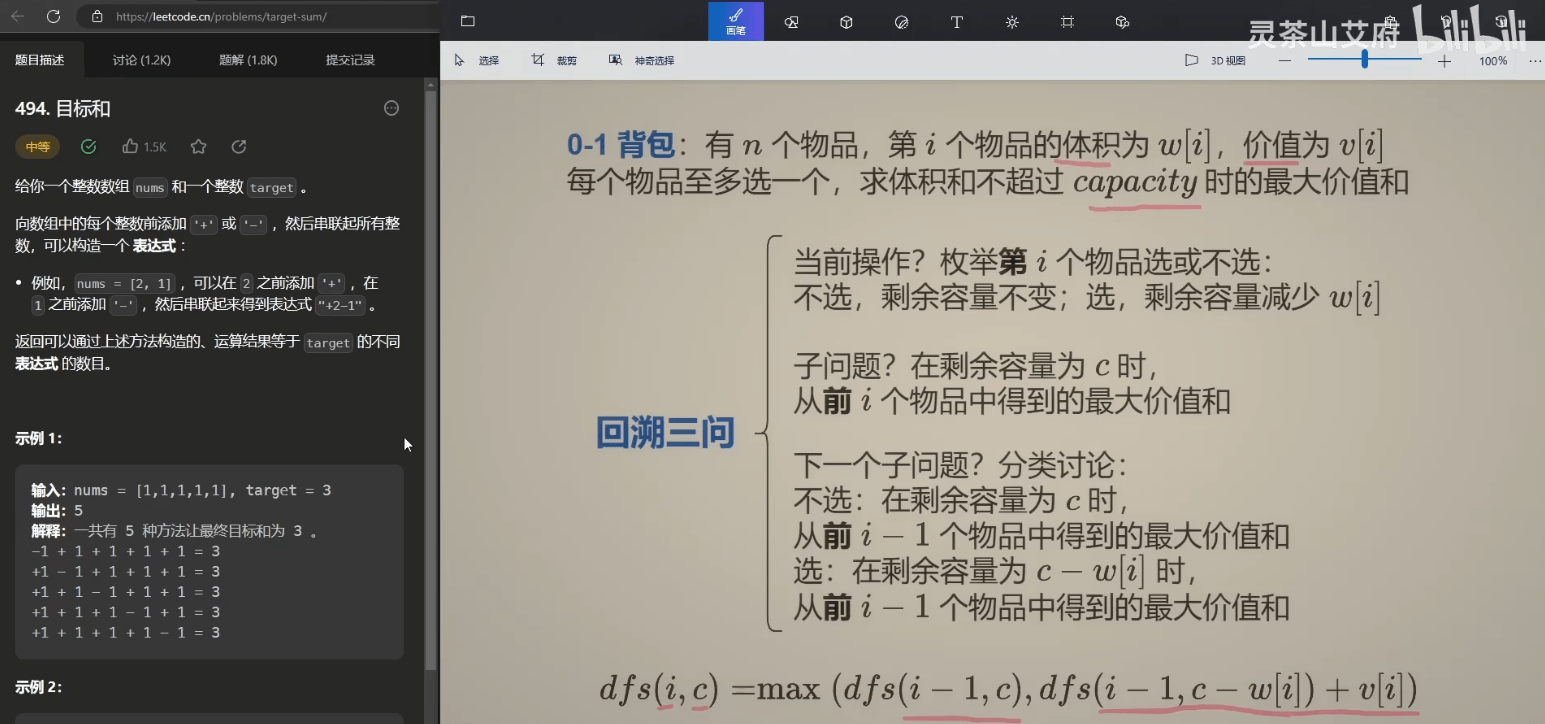
一、爬楼梯
简单
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶提示:
1 <= n <= 45
1.1 暴力递归(TLE)
class Solution {
/**
* 70. 爬楼梯(暴力递归)
*
* @param n 楼梯阶数
* @return 方案总数
*/
public int climbStairs(int n) {
if (n == 0) return 1;
if (n < 0) return 0;
return climbStairs(n - 1) + climbStairs(n - 2);
}
}时间复杂度O(2 ^ N),超时
1.2 记忆化递归
重复计算太多了导致暴力递归超时,如果能直接拿出上一次递归的结果,即f (n) = f (n - 1) + f (n - 2),那么就可以规避大量重复计算
class Solution {
/**
* 70. 爬楼梯(记忆化)
*
* @param n 楼梯阶数
* @return 方案总数
*/
public int climbStairs(int n) {
int[] memo = new int[n + 1];
return helper(n, memo);
}
private int helper(int n, int[] memo) {
if (n == 0) return 1;
if (n < 0) return 0;
if (memo[n] != 0) return memo[n]; // 避免重复计算
memo[n] = helper(n - 1, memo) + helper(n - 2, memo);
return memo[n];
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存41.56MB,击败7.36%,复杂度O(N)
1.3 模板dp
子问题:枚举选步长1或2
确定dp维数:本题只需要存储爬到第
i级楼梯的方案总数,系一维定义dp数组:
int[] dp = new int[n + 1];基本状态转移方程:
dp[i] = dp[i-1] + dp[i-2]初始状态:
dp[1] = 1、dp[2] = 2
class Solution {
/**
* 70. 爬楼梯(标准dp)
*
* @param n 楼梯阶数
* @return 方案总数
*/
public int climbStairs(int n) {
if (n <= 2) return n;
int[] dp = new int[n + 1];
dp[1] = 1;
dp[2] = 2;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存41.55MB,击败8.67%,复杂度O(N)
1.4 优化dp
由于我们只关心三个状态:dp[i] = dp[i - 1] + dp[i - 2];,迭代过去之后,之前的状态对于答案不重要了
于是可以用3个变量来代替数组存储
class Solution {
/**
* 70. 爬楼梯(滚动数组)
*
* @param n 楼梯阶数
* @return 方案总数
*/
public int climbStairs(int n) {
if (n <= 2) return n;
// 只需要3个变量:prev2, prev1, current
int prev2 = 1; // dp[i-2]
int prev1 = 2; // dp[i-1]
int current = 0;
for (int i = 3; i <= n; i++) {
current = prev1 + prev2; // 状态转移
prev2 = prev1; // 滚动更新
prev1 = current;
}
return current;
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存41.35MB,击败36.10%,复杂度O(1)
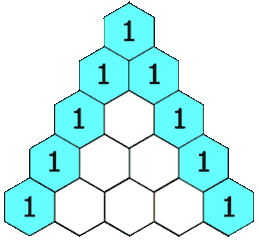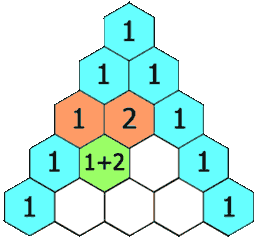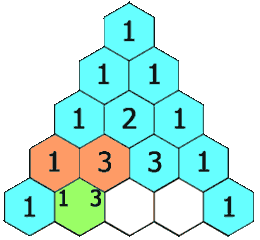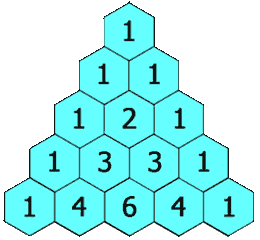
二、杨辉三角
简单
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
示例 1:
输入: numRows = 5
输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例 2:
输入: numRows = 1
输出: [[1]]提示:
1 <= numRows <= 30
2.1 dp
子问题:直接递推,每个值由上方两数确定
确定dp维数:本题需要由第
i-1层的杨辉三角系数计算下一层,系二维定义dp数组:
int[][] dp = new int[numRows + 1][];基本状态转移方程:
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j]初始状态:
dp[2][0] = 1、dp[2][1] = 1
/**
* 118. 杨辉三角(dp)
*
* @param n 层数
* @return 杨辉三角系数
*/
public List<List<Integer>> generate(int numRows) {
List<List<Integer>> ans = new ArrayList<>();
// 第一行
ans.add(new ArrayList<>(Arrays.asList(1)));
if (numRows == 1) return ans;
// 第二行
ans.add(new ArrayList<>(Arrays.asList(1, 1)));
if (numRows == 2) return ans;
// 初始状态
int[][] dp = new int[numRows + 1][];
dp[2] = new int[]{1, 1};
for (int i = 3; i <= numRows; i++) {
// 每一行的第一个设为1
List<Integer> temp = new ArrayList<>();
dp[i] = new int[numRows];
dp[i][0] = 1;
temp.add(dp[i][0]);
for (int j = 1; j < i - 1; j++) {
dp[i][j] = dp[i-1][j-1] + dp[i-1][j];
temp.add(dp[i][j]);
}
// 每一行的最后一个设为1
dp[i][i - 1] = 1;
temp.add(dp[i][i - 1]);
ans.add(temp);
}
return ans;
}执行用时1ms,击败99.48%,复杂度O(N^2)
消耗内存42.56MB,击败52.58%,复杂度O(N^2)
2.2 空间复杂度优化
注意到dp[][]和List<List<Integer>>有点重复存储了,可以直接利用答案集合作为dp[][]
状态转换方程如下:
cur = ans.get(i - 1).get(j - 1) + ans.get(i - 1).get(j);
/**
* 118. 杨辉三角(优化dp)
*
* @param n 层数
* @return 杨辉三角系数
*/
public List<List<Integer>> generate(int numRows) {
List<List<Integer>> ans = new ArrayList<>();
for (int i = 0; i < numRows; i++) {
List<Integer> row = new ArrayList<>();
for (int j = 0; j <= i; j++) {
if (j == 0 || j == i) {
row.add(1);
} else {
int left = ans.get(i - 1).get(j - 1);
int right = ans.get(i - 1).get(j);
row.add(left + right);
}
}
ans.add(row);
}
return ans;
}除去返回集合的开销,空间复杂度为O(1)
三、打家劫舍
中等
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。示例 2:
输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。提示:
1 <= nums.length <= 1000 <= nums[i] <= 400
3.1 dp
对于第i间屋子,只有如下情况:
- 打劫
- 说明上一家没打劫,当前最大金额为
dp[i - 2] + nums[i]
- 说明上一家没打劫,当前最大金额为
- 不打劫
- 说明当前最大金额为偷到第
i - 1间房子的最大金额dp[i - 1] - ❓不能连续俩家不打劫吗,即
...偷 不 不 偷...dp[i-1]包含了所有偷到第i-1间房子的最优方案- 如果最优方案没偷第i-1间,那它一定偷了第i-2间
- 所以
dp[i-1]已经隐含了”跳过2个房子”的情况
- 说明当前最大金额为偷到第
子问题:选或不选
确定dp维数:本题需要存储前
i家能打劫到的最大金额,系一维定义dp数组:
int[] dp = new int[length];基本状态转移方程:
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);初始状态:
dp[0] = nums[0];、dp[1] = Math.max(nums[0], nums[1]);
class Solution {
/**
* 198. 打家劫舍(dp)
*
* @param nums 每家金额
* @return 最大金额
*/
public int rob(int[] nums) {
int length = nums.length;
if (length == 1) return nums[0];
int[] dp = new int[length];
dp[0] = nums[0];
dp[1] = Math.max(nums[0], nums[1]);
for (int i = 2; i < length; i++) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
}
return dp[length - 1];
}
}空间复杂度O(N)
3.2 空间复杂度优化
与前边俩题类似,可以改为只用俩个变量来滚动存储dp[i - 1]、dp[i - 2]
以i = 2为例,dp[2] = Math.max(dp[0] + nums[2], dp[1]),赋值后,dp[2]就是新的dp1,原来的dp1变成了dp0
class Solution {
/**
* 198. 打家劫舍(优化dp)
*
* @param nums 每家金额
* @return 最大金额
*/
public int rob(int[] nums) {
int length = nums.length;
if (length == 1) return nums[0];
int dp0 = nums[0], dp1 = Math.max(nums[0], nums[1]);
for (int i = 2; i < length; i++) {
int temp = dp1; // 记录旧的dp1
dp1 = Math.max(dp0 + nums[i], dp1); // 更新dp1
dp0 = temp; // 把dp1赋给dp0
}
return dp1;
}
}空间复杂度O(1)
四、完全平方数
中等
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4示例 2:
输入:n = 13
输出:2
解释:13 = 4 + 9提示:
1 <= n <= 10^4
4.1 dp
定义:dp[j] = 组成数字 j 所需的最少完全平方数个数
对于每个平方数 i * i 和每个数字 j,有两种选择:
- 不选→
dp[j] = dp[j] - 选→
dp[j]取自己和dp[j - i * i] + 1之间的最小值
- 比如
j = 8,i = 2 - 则有
dp[8] = dp[8 - 2 * 2] + 1 = dp[4] + 1 = dp[0] + 2,体现了可重复选同一个数
子问题:选或不选该平方数
确定dp维数:本题需要存储整数
i的完全平方数的最少数量,系一维定义dp数组:
int[] dp = new int[n + 1];基本状态转移方程:
dp[j] = Math.min(dp[j], dp[j - i * i] + 1);初始状态:
dp[i] = i;
class Solution {
/**
* 279. 完全平方数(dp)
*
* @param n 目标数
* @return 最少平方数
*/
public int numSquares(int n) {
int[] dp = new int[n + 1];
// 初始化dp数组
for (int i = 0; i <= n; i++) {
dp[i] = i; // 最坏情况:全用1
}
// 遍历完全平方数
for (int i = 2; i * i <= n; i++) {
int square = i * i;
// 更新dp数组
for (int j = square; j <= n; j++) {
dp[j] = Math.min(dp[j], dp[j - square] + 1);
}
}
return dp[n];
}
}执行用时27ms,击败69.23%,复杂度O(N * sqrt(N))
消耗内存43.98MB,击败13.80%,复杂度O(N)
4.2 过程可视化
初始化后:
dp[0] = 0
dp[1] = 1
dp[2] = 2
dp[3] = 3
dp[4] = 4
dp[5] = 5
dp[6] = 6
dp[7] = 7
dp[8] = 8
dp[9] = 9
dp[10] = 10
dp[11] = 11
dp[12] = 12循环第1轮:i=2, square=4
j=4:
dp[4] = Math.min(dp[4]=4, dp[4-4]=dp[0]=0 + 1=1) = 1
dp数组变为:dp[4]=1
j=5:
dp[5] = Math.min(dp[5]=5, dp[5-4]=dp[1]=1 + 1=2) = 2
dp数组变为:dp[5]=2
j=6:
dp[6] = Math.min(dp[6]=6, dp[6-4]=dp[2]=2 + 1=3) = 3
dp数组变为:dp[6]=3
j=7:
dp[7] = Math.min(dp[7]=7, dp[7-4]=dp[3]=3 + 1=4) = 4
dp数组变为:dp[7]=4
j=8:
dp[8] = Math.min(dp[8]=8, dp[8-4]=dp[4]=1 + 1=2) = 2 // 这里dp[4]已经是1了
dp数组变为:dp[8]=2
j=9:
dp[9] = Math.min(dp[9]=9, dp[9-4]=dp[5]=2 + 1=3) = 3
dp数组变为:dp[9]=3
j=10:
dp[10] = Math.min(dp[10]=10, dp[10-4]=dp[6]=3 + 1=4) = 4
dp数组变为:dp[10]=4
j=11:
dp[11] = Math.min(dp[11]=11, dp[11-4]=dp[7]=4 + 1=5) = 5
dp数组变为:dp[11]=5
j=12:
dp[12] = Math.min(dp[12]=12, dp[12-4]=dp[8]=2 + 1=3) = 3
dp数组变为:dp[12]=3循环第2轮:i=3, square=9
j=9:
dp[9] = Math.min(dp[9]=3, dp[9-9]=dp[0]=0 + 1=1) = 1
dp数组变为:dp[9]=1
j=10:
dp[10] = Math.min(dp[10]=4, dp[10-9]=dp[1]=1 + 1=2) = 2
dp数组变为:dp[10]=2
j=11:
dp[11] = Math.min(dp[11]=5, dp[11-9]=dp[2]=2 + 1=3) = 3
dp数组变为:dp[11]=3
j=12:
dp[12] = Math.min(dp[12]=3, dp[12-9]=dp[3]=3 + 1=4) = 3
// 因为3 < 4
dp数组保持:dp[12]=34.3 *拉格朗日四平方和
这是一种数学解法,由ai老师告知得来,百度百科:四平方和定理↗,不需掌握
class Solution {
public int numSquares(int n) {
// 定理:任何正整数可以表示为4个整数的平方和
// 1. 检查是否是完全平方数
if (isSquare(n)) return 1;
// 2. 检查是否是两个平方数之和
for (int i = 1; i * i <= n; i++) {
if (isSquare(n - i * i)) return 2;
}
// 3. 根据勒让德三平方和定理
// n != 4^k*(8m+7) 时,可以是3个平方数
while (n % 4 == 0) {
n /= 4;
}
if (n % 8 == 7) return 4;
// 4. 其他情况为3
return 3;
}
private boolean isSquare(int n) {
int sqrt = (int) Math.sqrt(n);
return sqrt * sqrt == n;
}
}五、零钱兑换
中等
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1示例 2:
输入:coins = [2], amount = 3
输出:-1示例 3:
输入:coins = [1], amount = 0
输出:0提示:
1 <= coins.length <= 121 <= coins[i] <= 2^31 - 10 <= amount <= 10^4
5.1 dp
与上一题完全平方数类似,把平方改成了硬币数组而已
定义:dp[j] = 组成金钱 j 所需的最少完全平方数个数
对于每个平方数 i * i 和每个数字 j,有两种选择:
- 不选→
dp[j] = dp[j] - 选→
dp[j]取自己和dp[j - coins[i]] + 1之间的最小值
子问题:选或不选该面值的硬币
确定dp维数:本题需要存储组成金钱
i的最少数量,系一维定义dp数组:
int[] dp = new int[amount + 1];基本状态转移方程:
dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);初始状态:
dp[0] = 0;、其他为amount + 1,即在此题中表示不可达(无穷大)
class Solution {
/**
* 322. 零钱兑换(dp)
*
* @param coins 硬币面值数组
* @param amount 目标金额
* @return 最少金币数
*/
public int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
Arrays.fill(dp, amount + 1);
dp[0] = 0;
for (int i = 0; i < coins.length; i++) {
for (int j = coins[i]; j <= amount; j++) {
dp[j] = Math.min(dp[j], dp[j - coins[i]] + 1);
}
}
return dp[amount] < amount + 1 ? dp[amount] : -1;
}
}六、单词拆分
中等
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅由小写英文字母组成wordDict中的所有字符串 互不相同
6.1 记忆化递归
如果s能被分割为若干个小字符串,那一定可以从头到尾挨个分割
对于cat和cats情况,说明需要尝试每个可能的终止点,并以该终止点作为下次递归的起点
由于字典里的单词可以重复使用,并且我们只关心能不能由字典里边的单词构成
- 所以可以把字典放入一个
HashSet中,每次分割小字符串后判断是否contains即可
class Solution {
/**
* 139. 单词拆分(记忆化)
*
* @param s 目标字符串
* @param wordDict 字典
* @return 字典中的单词能否拼接成目标字符串
*/
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> words = new HashSet<>(wordDict);
return dfs(s, words, 0, new Boolean[s.length()]);
}
private boolean dfs(String s, Set<String> words, int start, Boolean[] memo) {
int length = s.length();
// 如果递归到了尽头,说明可以分割
if (start == length) return true;
if (memo[start] != null) return memo[start];
for (int end = start + 1; end <= length; end++) {
String word = s.substring(start, end);
// 如果字典中包含该子串
if (words.contains(word)) {
// 以当前终点为新的起点递归
if (dfs(s, words, end, memo)) {
memo[start] = true;
return true;
}
}
}
memo[start] = false;
return false;
}
}执行用时6ms,击败72.03%,复杂度O(N^2)
消耗内存45.44MB,击败23.18%,复杂度O(N)
6.2 dp
把上边记忆化改成迭代,在每个合法分割起点处寻找所有可能的终点,最后判断能否到达字符串s末尾
子问题:枚举所有可能的起始点
确定dp维数:本题需要存储:
s中,由下标i为起点的子串是否在字典中,系一维定义dp数组:
boolean[] dp = new boolean[length + 1];基本状态转移方程:
dp[j] = dp[i];初始状态:
dp[0] = 0;
class Solution {
/**
* 139. 单词拆分(dp)
*
* @param s 目标字符串
* @param wordDict 字典
* @return 字典中的单词能否拼接成目标字符串
*/
public boolean wordBreak(String s, List<String> wordDict) {
Set<String> words = new HashSet<>(wordDict);
int length = s.length();
boolean[] dp = new boolean[length + 1];
dp[0] = true; // 首字母是合法分割起点
for (int i = 0; i <= length; i++) {
// 判断是否为合法分割起点
if (!dp[i]) continue;
for (int j = i + 1; j <= length; j++) {
String word = s.substring(i, j);
// 如果字典中包含该子串
if (words.contains(word)) {
dp[j] = dp[i];
}
}
}
return dp[length];
}
}执行用时9ms,击败39.80%,复杂度O(N^2)
消耗内存45.36MB,击败29.40%,复杂度O(N)
七、最长递增子序列
中等
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:
输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。示例 2:
输入:nums = [0,1,0,3,2,3]
输出:4示例 3:
输入:nums = [7,7,7,7,7,7,7]
输出:1提示:
1 <= nums.length <= 2500-10^4 <= nums[i] <= 10^4
进阶:
- 你能将算法的时间复杂度降低到
O(n log(n))吗?
7.1 dp
尝试以数组nums的每个元素为起始索引,dp中存储以当前下标为起点、到数组末尾比它大的数
子问题:枚举所有可能的起始点
确定dp维数:本题需要存储由下标
i为起点的子序列的严格递增长度,系一维定义dp数组:
int[] dp = new int[length];基本状态转移方程:
dp[j] = Math.max(dp[j], dp[i] + 1);初始状态:
dp = 1
- 若
i < j且nums[i] < nums[j],则可以把“以 i 结尾的递增序列”再接上nums[j],得到一个“以 j 结尾”的长度dp[i] + 1 - j 可能有多个前驱 i(不同位置都能接到 j),因此以 j 结尾的最优值应取这些候选中的最大值以及它原来的值:
dp[j] = max(dp[j], dp[i] + 1)
class Solution {
/**
* 300. 最长递增子序列(dp,枚举起点)
*
* @param nums 原始数组
* @return 最长严格递增子序列的长度
*/
public int lengthOfLIS(int[] nums) {
int length = nums.length;
int[] dp = new int[length];
int ans = 1;
Arrays.fill(dp, 1);
for (int i = 0; i < length; i++) {
// 如果即使把后面所有位置都接上,长度也不可能超过 ans,就跳过 i
if (dp[i] + (length - i - 1) <= ans) continue;
for (int j = i + 1; j < length; j++) {
if (nums[i] < nums[j]) {
dp[j] = Math.max(dp[j], dp[i] + 1);
ans = Math.max(ans, dp[j]);
}
}
}
return ans;
}
}执行用时64ms,击败44.25%,复杂度O(N^2)
消耗内存45.11MB,击败51.84%,复杂度O(N)
class Solution {
/**
* 300. 最长递增子序列(dp,枚举终点)
*
* @param nums 原始数组
* @return 最长严格递增子序列的长度
*/
public int lengthOfLIS(int[] nums) {
int length = nums.length;
int[] dp = new int[length];
int ans = 1;
Arrays.fill(dp, 1);
for (int i = 0; i < length; i++) {
for (int j = 0; j < i; j++) {
if (nums[j] < nums[i]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
ans = Math.max(ans, dp[i]);
}
}
}
return ans;
}
}
7.2 贪心 + 二分查找
上边的解法,定义dp[i]表示:终点元素 为 nums[i]的最大子序列长度
灵神的进阶技巧👉(最长递增子序列【基础算法精讲 20】_哔哩哔哩_bilibili↗):交换状态与状态值
即定义dp[i]表示:长度为i + 1的子序列的末尾元素的最小值
例如nums = [1, 6, 7, 2, 4, 5, 3]
- 遍历到元素1,dp = [1]
- 遍历到元素6,dp = [1, 6]
- 遍历到元素7,dp = [1, 6, 7]
- 遍历到元素2,dp = [1, 2, 7]
- 遍历到元素4,dp = [1, 2, 4]
- 遍历到元素5,dp = [1, 2, 4, 5]
- 遍历到元素3,dp = [1, 2, 3, 5]
class Solution {
/**
* 300. 最长递增子序列(贪心 + 二分查找)
*
* @param nums 原始数组
* @return 最长严格递增子序列的长度
*/
public int lengthOfLIS(int[] nums) {
int length = nums.length;
List<Integer> greedy = new ArrayList<>();
for (int n : nums) {
int l = 0, r = greedy.size();
while (l < r) {
int m = (l + r) >> 1;
if (n > greedy.get(m)) l = m + 1; // 如果当前元素比中点元素还要大
else r = m;
}
if (l == greedy.size()) greedy.add(n);
else greedy.set(l, n);
}
return greedy.size();
}
}执行用时5ms,击败85.88%,复杂度O(N^2)
消耗内存45.26MB,击败35.53%,复杂度O(N)
八、乘积最大子数组
中等
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续 子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。
测试用例的答案是一个 32-位 整数。
请注意,一个只包含一个元素的数组的乘积是这个元素的值。
示例 1:
输入: nums = [2,3,-2,4]
输出: 6
解释: 子数组 [2,3] 有最大乘积 6。示例 2:
输入: nums = [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。提示:
1 <= nums.length <= 2 * 10^4-10 <= nums[i] <= 10nums的任何子数组的乘积都 保证 是一个 32-位 整数
8.1 dp
只要nums[i] != 0,一定有|nums[i]| >= 1,所以连续乘积的绝对值是在一直增大的,乘积的正负会因负数个数变化而翻转,仅用一个max无法表达“最大/最小”的转移关系,因此需要额外定义一个min来存储最小值,遇到负数直接交换最大最小值即可
子问题:枚举所有可能的终点
确定dp维数:本题需要存储由下标
i为终点的子序列的最大 / 最小连乘,系一维定义dp初始状态:
int min = nums[0], max = nums[0];基本状态转移方程:
m?? = Math.m??(nums[i] * m??, nums[i]);
class Solution {
/**
* 152. 乘积最大子数组(dp,枚举终点)
*
* @param nums 原始数组
* @return 最大子序列乘积
*/
public int maxProduct(int[] nums) {
int length = nums.length;
int min = nums[0], max = nums[0], ans = nums[0];
for (int i = 1; i < length; i++) {
if (nums[i] < 0) { // 如果当前元素 < 0,由于|nums[i]| >= 1,故交换最大最小值
int temp = min;
min = max;
max = temp;
}
max = Math.max(nums[i] * max, nums[i]); // 累计计数或者重新计数
min = Math.min(nums[i] * min, nums[i]);
ans = Math.max(ans, max);
}
return ans;
}
}九、分割等和子集
中等
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。提示:
1 <= nums.length <= 2001 <= nums[i] <= 100
9.1 dp
由于nums只含正整数,如果能分割,说明nums每个元素之和sum一定是偶数
- 于是问题变成:在
nums中,抽出若干个元素,使得它们的和恰为sum / 2 - 对于
nums中的每个元素,只有抽或不抽俩个选择
子问题:选或不选
确定dp维数:本题需要存储元素和能否为 1 到数组和一半 的每个数,系一维
定义dp数组:
boolean[] dp = new boolean[sum + 1];基本状态转移方程:
dp[j] = dp[j] || dp[j - n];初始状态:
dp[0] = true;
class Solution {
/**
* 416. 分割等和子集(dp)
*
* @param nums 原始数组
* @return 最大子序列乘积
*/
public boolean canPartition(int[] nums) {
int sum = 0;
for (int n : nums) sum += n;
if (sum % 2 != 0) return false;
sum = sum >> 1;
int length = nums.length;
boolean[] dp = new boolean[sum + 1];
dp[0] = true;
for (int n : nums) {
for (int j = sum; j >= n; j--) {
dp[j] = dp[j] || dp[j - n];
}
if (dp[sum]) return true;
}
return false;
}
}十、 最长有效括号
困难
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号 子串 的长度。
左右括号匹配,即每个左括号都有对应的右括号将其闭合的字符串是格式正确的,比如 "(()())"。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"示例 2:
输入:s = ")()())"
输出:4
解释:最长有效括号子串是 "()()"示例 3:
输入:s = ""
输出:0提示:
0 <= s.length <= 3 * 10^4s[i]为'('或')'
10.1 栈
维护一个boolean[] arr = new boolean[length];,记录s对应下标处的括号是否有效
通过栈,左括号入栈,右括号弹出,并标记该下标为有效
处理完后遍历boolean[] arr,找到最大连续true长度即可
class Solution {
/**
* 32. 最长有效括号(栈,暴力)
*
* @param s 括号字符串
* @return 最长有效长度
*/
public int longestValidParentheses(String s) {
int length = s.length();
boolean[] arr = new boolean[length];
Deque<Integer> stack = new ArrayDeque<>();
for (int i = 0; i < length; i++) {
if (s.charAt(i) == '(') stack.push(i);
else if (!stack.isEmpty()) {
arr[i] = true;
arr[stack.pop()] = true;
}
}
int ans = 0;
for (int i = 0; i < length;) {
int temp = 0;
while (i < length && arr[i++]) temp++;
ans = Math.max(ans, temp);
}
return ans;
}
}执行用时4ms,击败44.27%,复杂度O(N)
消耗内存45.87MB,击败21.68%,复杂度O(N)
class Solution {
/**
* 32. 最长有效括号(栈,单次遍历)
*
* @param s 括号字符串
* @return 最长有效长度
*/
public int longestValidParentheses(String s) {
Deque<Integer> stack = new ArrayDeque<>();
stack.push(-1); // 哨兵:上一个不匹配位置
int ans = 0;
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) == '(') {
stack.push(i);
} else {
stack.pop();
if (stack.isEmpty()) {
stack.push(i); // 当前 ) 不匹配,更新基准
} else {
ans = Math.max(ans, i - stack.peek()); // 以 i 结尾的有效长度
}
}
}
return ans;
}
}执行用时6ms,击败18.36%,复杂度O(N)
消耗内存45.82MB,击败23.83%,复杂度O(N)
两者都是 O(N),但常数项不同;再加上 Java 的实现细节、JIT 与测评噪声,单次遍历未必更快。
“单次遍历”版本在每个字符上做了更多分支与方法调用(尤其是 Deque<Integer>的装箱/出栈/取栈顶)
而“两次遍历”版本第二遍只是顺序扫 boolean[],分支更少、更友好于 CPU 缓存,所以常数更小、跑得更稳。
10.2 dp
如果当前括号是合法有效的,那么只能是: ()或 ))
s = ( ( ) ( ) ( ) ( ( )
dp = 0 0 2 0 4 0 6 0 0 2
当 s[i] = ')' 且 s[i-1] = '(' 时:
dp[i] = dp[i-2] + 2
↑ ↑
当前长度 前前位置的有效长度s = ( ( ) ( ) ( ) ) ( ( ) )
dp = 0 0 2 0 4 0 6 8 0 0 2 12
当 s[i] = ')' 且 s[i-1] = ')' 时:
需要找到与当前 ')' 匹配的 '('
匹配位置 = i - dp[i-1] - 1
👆举例:当前位置:i=11, s[11]=')'
前一个:i-1=10, s[10]=')', dp[10]=2
匹配位置:11-2-1=8, s[8]='('
计算:dp[11] = 2 + 2 + dp[7] = 4 + 8 = 12
对应整个字符串:"(()()())(())"(索引0-11,长度12)
如果 s[匹配位置] = '(',则:
dp[i] = dp[i-1] + 2 + dp[匹配位置-1]
↑ ↑ ↑
内部长度 当前匹配 前面有效长度子问题:枚举所有可能的终点
确定dp维数:本题需要存储由下标
i为终点的最长有效长度,系一维定义dp数组:
int[] dp = new int[length + 2];(注意所有dp数组元素右移2个单位长度)基本状态转移方程:
- 对于“()”,
dp[i + 2] = dp[i] + 2;- 对于“))”,
dp[i + 2] = prevLen + 2 + dp[i - prevLen];初始状态:额外定义dp数组多俩个长度,不需要处理初始状态
class Solution {
/**
* 32. 最长有效括号(dp)
*
* @param s 括号字符串
* @return 最长有效长度
*/
public int longestValidParentheses(String s) {
int length = s.length();
int ans = 0;
int[] dp = new int[length + 2];
for (int i = 0; i < length; i++) {
if (s.charAt(i) == ')') {
// 匹配 "()"
if (i > 0 && s.charAt(i - 1) == '(') {
dp[i + 2] = dp[i] + 2;
}
// 匹配 "))"
else if (i > 0 && s.charAt(i - 1) == ')') {
int prevLen = dp[i + 1]; // 前一个有效长度
if (prevLen > 0 && i - prevLen - 1 >= 0 && s.charAt(i - prevLen - 1) == '(') {
dp[i + 2] = prevLen + 2 + dp[i - prevLen];
}
}
ans = Math.max(ans, dp[i + 2]);
}
}
return ans;
}
}十一、 不同路径
中等
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
示例 1:

输入:m = 3, n = 7
输出:28示例 2:
输入:m = 3, n = 2
输出:3
解释:
从左上角开始,总共有 3 条路径可以到达右下角。
1. 向右 -> 向下 -> 向下
2. 向下 -> 向下 -> 向右
3. 向下 -> 向右 -> 向下示例 3:
输入:m = 7, n = 3
输出:28示例 4:
输入:m = 3, n = 3
输出:6提示:
1 <= m, n <= 100- 题目数据保证答案小于等于
2 * 10^9
11.1 数学解法
由于只能向右或向下走(不走回头路)
所以从左上角到右下角的路线长度总和是固定的m + n - 2
在m + n - 2中,需要抽出m - 1步向右走,n - 1步向左走,用组合数公式即可计算
class Solution {
/**
* 62. 不同路径(数学解法,但溢出)
*
* @param m 网格图的长
* @param n 网格图的宽
* @return 路径总数
*/
public int uniquePaths(int m, int n) {
return factorial(n + m - 2) / factorial(m - 1) / factorial(n - 1);
}
private int factorial(int x) {
if (x == 0) return 1;
return x * factorial(x - 1);
}
}很明显,m、n一大直接爆int
在算法中,(a + b) / 2常写作b + (a - b) / 2,因为如果a、b都为大数,a + b直接就爆int了
class Solution {
/**
* 62. 不同路径(数学解法)
*
* @param m 网格图的长
* @param n 网格图的宽
* @return 路径总数
*/
public int uniquePaths(int m, int n) {
return (int) chooseSum(m - 1, n - 1);
}
private long chooseSum(int a, int b) {
if (a < 0 || b < 0) return -1;
int n = a + b;
int k = Math.min(a, b);
long res = 1;
for (int i = 1; i <= k; i++) {
res = res * (n - k + i) / i; // 一定能整除
}
return res;
}
}执行用时0ms,击败100.00%,复杂度O(min(m, n))
消耗内存41.30MB,击败54.93%,复杂度O(1)
11.2 dp
本题要求的是路径数,不是步长数,dP状态记录的是路径数量,不是步数
由于只能向右或向下走,到达(i, j)的路径总数等于上一个状态再向右走或向下走,即俩种情况的总和
子问题:固定前驱求和
确定dp维数:本题需要存储坐标
(i, j)为终点的路径总数,系二维定义dp数组:
int[][] dp = new int[m + 1][n + 1];基本状态转移方程:
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];初始状态:
dp[1][2] = 1; dp[2][1] = 1;
class Solution {
/**
* 62. 不同路径(dp)
*
* @param m 网格图的长
* @param n 网格图的宽
* @return 路径总数
*/
public int uniquePaths(int m, int n) {
int[][] dp = new int[m + 1][n + 1];
dp[1][0] = 1;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
}
}
return dp[m][n];
}
}执行用时0ms,击败100.00%,复杂度O(m * n)
消耗内存41.38MB,击败45.38%,复杂度O(m * n)
十二、最小路径和
中等
给定一个包含非负整数的 *m* x *n* 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
说明:每次只能向下或者向右移动一步。
示例 1:
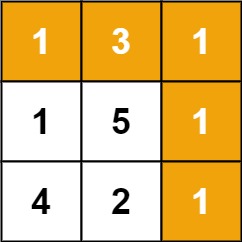
输入:grid = [[1,3,1],[1,5,1],[4,2,1]]
输出:7
解释:因为路径 1→3→1→1→1 的总和最小。示例 2:
输入:grid = [[1,2,3],[4,5,6]]
输出:12提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 2000 <= grid[i][j] <= 200
12.1 dp
本题要求的是权值和,不是路径数,与上一道题不一样
子问题:固定前驱求和
确定dp维数:本题需要存储坐标
(i, j)为终点的最小权值和,系二维定义dp数组:
int[][] dp = new int[m + 1][n + 1];基本状态转移方程:
dp[i][j] = dp[i - 1][j] + dp[i][j - 1];初始状态:
dp[0][i] = Integer.MAX_VALUE; dp[i][0] = Integer.MAX_VALUE;最后设置
dp[1][0]或dp[0][1]为0(作为迭代起点)
class Solution {
/**
* 64. 最小路径和(dp)
*
* @param grid 路径权值二维数组
* @return 路径权值最小和
*/
public int minPathSum(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
int[][] dp = new int[m + 1][n + 1];
for (int i = 0; i <= m; i++) dp[i][0] = Integer.MAX_VALUE;
for (int i = 0; i <= n; i++) dp[0][i] = Integer.MAX_VALUE;
dp[1][0] = 0;
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
dp[i][j] = Math.min(dp[i - 1][j], dp[i][j - 1]) + grid[i - 1][j - 1];
}
}
return dp[m][n];
}
}12.2 dp空间优化
可以用grid本身记录已走过格子的权值最小和,不用额外定义dp[][]
class Solution {
/**
* 64. 最小路径和(dp,无额外空间)
*
* @param grid 路径权值二维数组
* @return 路径权值最小和
*/
public int minPathSum(int[][] grid) {
int m = grid.length, n = grid[0].length;
for (int j = 1; j < n; j++) {
grid[0][j] += grid[0][j - 1];
}
for (int i = 1; i < m; i++) {
grid[i][0] += grid[i - 1][0];
}
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
grid[i][j] += Math.min(grid[i - 1][j], grid[i][j - 1]);
}
}
return grid[m - 1][n - 1];
}
}十三、最长回文子串
中等
给你一个字符串 s,找到 s 中最长的 回文 子串。
示例 1:
输入:s = "babad"
输出:"bab"
解释:"aba" 同样是符合题意的答案。示例 2:
输入:s = "cbbd"
输出:"bb"提示:
1 <= s.length <= 1000s仅由数字和英文字母组成
13.1 dp
在前文的回溯章节中,有一道缝合此题的回文串题目
/**
* 131. 分割回文串(dp + 回溯)
*
* @param s 要分割的字符串
* @return 所有分割完且是回文串的集合
*/
...
// DP预处理:计算所有子串是否是回文
for (int j = 0; j < n; j++) {
for (int i = 0; i <= j; i++) {
if (s.charAt(i) == s.charAt(j) && (j - i <= 2 || dp[i + 1][j - 1])) {
dp[i][j] = true;
}
}
}
...仿造如上写法,得到👇
class Solution {
/**
* 5. 最长回文子串(dp)
*
* @param grid 路径权值二维数组
* @return 路径权值最小和
*/
public String longestPalindrome(String s) {
int length = s.length();
boolean[][] dp = new boolean[length][length];
int start = 0, maxLen = 1;
for (int j = 0; j < length; j++) {
dp[j][j] = true; // 单个字符
for (int i = 0; i < j; i++) {
if (s.charAt(i) == s.charAt(j) && (j - i <= 2 || dp[i + 1][j - 1])) {
dp[i][j] = true;
if (j - i + 1 > maxLen) {
maxLen = j - i + 1;
start = i;
}
}
}
}
return s.substring(start, start + maxLen);
}
}执行用时113ms,击败43.50%,复杂度O(N^2)
消耗内存47.35MB,击败20.02%,复杂度O(N^2)
13.2 中心扩展
可以枚举每个点作为回文中心,尝试扩展,如果长度出现新高,更新最大值
class Solution {
/**
* 5. 最长回文子串(中心扩展)
*
* @param grid 路径权值二维数组
* @return 路径权值最小和
*/
public String longestPalindrome(String s) {
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
// 以单个字符为中心
int len1 = expand(s, i, i);
// 以两个字符为中心
int len2 = expand(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expand(String s, int left, int right) {
while (left >= 0 && right < s.length() && s.charAt(left) == s.charAt(right)) {
left--;
right++;
}
return right - left - 1; // 回文长度
}
}执行用时14ms,击败87.19%,复杂度O(N^2)
消耗内存42.96MB,击败71.74%,复杂度O(1)
十四、最长公共子序列
中等
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace" ,它的长度为 3 。示例 2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是 "abc" ,它的长度为 3 。示例 3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回 0 。提示:
1 <= text1.length, text2.length <= 1000text1和text2仅由小写英文字符组成。
14.1 二维dp
class Solution {
/**
* 1143. 最长公共子序列(二维dp)
*
* @param text1 字符串1
* @param text2 字符串2
* @return 最长公共子序列
*/
public int longestCommonSubsequence(String text1, String text2) {
int length1 = text1.length(), length2 = text2.length();
int[][] dp = new int[length1 + 1][length2 + 1];
for (int i = 1; i <= length1; i++) {
char cur = text1.charAt(i - 1);
for (int j = 1; j <= length2; j++) {
if (cur == text2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
return dp[length1][length2];
}
}执行用时12ms,击败84.31%,复杂度O(length1 * length2)
消耗内存53.14MB,击败16.29%,复杂度O(length1 * length2)
14.2 一维dp
由于不知道text1和text2的长度大小,直接遍历需要考虑更复杂的边界情况
采用if (text1.length() > text2.length()) return longestCommonSubsequence(text2, text1);
以确保text1的长度一定小于等于text2
尝试以数组text2的每个元素为结束位置,dp中存储以当前下标为终点的最长公共子序列长度
如果text1的第i个字符和text2的第j个字符相等,那么最长公共子序列的长度应该是:text1的前i-1个字符和text2的前j-1个字符时的最长公共子序列长度加1。即dp[j] = dp[j-1] + 1,这个值在更新dp[j]之前,实际上存储在dp[j-1]吗❓
- 不对,因为dp[j-1]已经被更新为text1的前i个字符和text2的前j-1个字符时的值了。当我们更新dp[j]时,dp[j-1]已经被更新了,所以我们无法从dp[j-1]得到我们需要的那个值。
- 所以我们需要一个变量
memo来记录未更新前的dp[j-1]
子问题:枚举所有可能的起始点
确定dp维数:本题需要存储由下标
i为终点的子序列长度,系一维定义dp数组:
int[] dp = new int[length2 + 1];基本状态转移方程:
if (text.charAt(i - 1) == text2.charAt(j - 1)) { dp[j] = memo + 1; } else dp[j] = Math.max(dp[j], dp[j - 1]);初始状态:
dp[0] = 0
class Solution {
/**
* 1143. 最长公共子序列(一维dp)
*
* @param text1 字符串1
* @param text2 字符串2
* @return 最长公共子序列
*/
public int longestCommonSubsequence(String text1, String text2) {
if (text1.length() > text2.length()) return longestCommonSubsequence(text2, text1);
int length1 = text1.length(), length2 = text2.length();
int[] dp = new int[length2 + 1];
int max = 0;
for (int i = 1; i <= length1; i++) {
char cur = text1.charAt(i - 1);
int memo = 0;
for (int j = 1; j <= length2; j++) {
int origin = dp[j]; // 记录的dp[j]对于下次循环来说就是未更新的dp[j-1]
if (cur == text2.charAt(j - 1)) {
dp[j] = memo + 1;
} else dp[j] = Math.max(dp[j], dp[j - 1]);
memo = origin;
}
}
return dp[length2];
}
}执行用时10ms,击败92.43%,复杂度O(length1 * length2)
消耗内存41.83MB,击败98.15%,复杂度O(length1 + 1)
十五、编辑距离
中等
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
示例 1:
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')示例 2:
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')提示:
0 <= word1.length, word2.length <= 500word1和word2由小写英文字母组成
15.1 LCS误解
注意到操作字母具有任意性,即:我可以直接把错误的字母改成正确的,也可以直接加上一个正确的字母,亦或是直接删除一个多余的
要使操作数最少,只需要先找出word1和word2的最长公共子序列(即上一题)
这些字母是不需要操作的,用word2.length()减去这些不需要操作的字母,则题目等价于只需要处理剩下的字母
class Solution {
/**
* 72. 编辑距离(LCS错误解答)
*
* @param word1 源单词
* @param word2 目标单词
* @return 最小编辑距离
*/
public int minDistance(String word1, String word2) {
int length1 = word1.length(), length2 = word2.length();
int[][] dp = new int[length1 + 1][length2 + 1];
for (int i = 1; i <= length1; i++) {
char cur = word1.charAt(i - 1);
for (int j = 1; j <= length2; j++) {
if (cur == word2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
} else dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
int same = dp[length1][length2]; // 已经相同的字母个数
if (same == length2) return length1 - length2;
int diff = length2 - same; // word2中还差几个字母
return diff + Math.abs(length1 - length2); // 多则删,少则加
}
}来看俩个示例:
// 输入,最长公共子序列为os,长度2,(3-2)+(5-3)= 3,正确
word1 = "horse"
word2 = "ros"
// 输出
3
// 预期结果
3// 输入,最长公共子序列为etion,长度5,(9-5)+(9-9)= 4
word1 = "intention"
word2 = "execution"
// 输出
4
// 预期结果
5除去LCS后,剩下字母情况如下
word1 = "int n "
word2 = "ex cu "可以发现,word1需要先删去再添加一个字母才能变成word2
15.2 二维dp
编辑距离不是简单的”先找公共部分再补差异”,因为:
- 替换操作比”删除+插入”更高效
- 不同的对齐方式会产生不同的操作序列
三种操作的代码实现
- 删除:
dp[i-1][j] + 1(去掉word1的一个字符) - 插入:
dp[i][j-1] + 1(添加word2的一个字符) - 替换:
dp[i-1][j-1] + 1(改变word1的一个字符)
子问题:每个位置三种操作选最优
确定dp维数:本题需要存储将
word1[0:i]转换为word2[0:j]所需的最小操作数,系二维定义dp数组:
int[][] dp = new int[length1 + 1][length2 + 1];基本状态转移方程:
- 字符相同:
dp[i][j] = dp[i-1][j-1]- 字符不同:
dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1初始状态:
dp[i][0] = i(删除i次)dp[0][j] = j(插入j次)
class Solution {
/**
* 72. 编辑距离(二维dp)
*
* @param word1 源单词
* @param word2 目标单词
* @return 最小编辑距离
*/
public int minDistance(String word1, String word2) {
int length1 = word1.length(), length2 = word2.length();
int[][] dp = new int[length1 + 1][length2 + 1]; // word1前i个转换成word2前j个字符相同最少次数
for (int i = 1; i <= length2; i++) dp[0][i] = i;
for (int i = 1; i <= length1; i++) {
dp[i][0] = i;
for (int j = 1; j <= length2; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) dp[i][j] = dp[i - 1][j - 1];
else dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;
}
}
return dp[length1][length2];
}
}执行用时5ms,击败69.05%,复杂度O(N*M)
消耗内存46.59MB,击败5.08%,复杂度O(N*M)
15.3 一维dp
观察发现,计算 dp[i][j] 只需要:
- 上一行的
dp[i-1][j],即memo,替换操作 - 当前行的
dp[i][j-1],即origin,替换操作 - 上一行的
dp[i-1][j-1],即dp[j-1],插入操作
可以使用一维数组+ prev 变量优化
class Solution {
/**
* 72. 编辑距离(一维dp)
*
* @param word1 源单词
* @param word2 目标单词
* @return 最小编辑距离
*/
public int minDistance(String word1, String word2) {
int length1 = word1.length(), length2 = word2.length();
int[] dp = new int[length2 + 1]; // 转换成word2前j个字符最少次数
for (int i = 1; i <= length2; i++) dp[i] = i;
for (int i = 1; i <= length1; i++) {
int memo = dp[0];
dp[0] = i;
char cur = word1.charAt(i - 1);
for (int j = 1; j <= length2; j++) {
int origin = dp[j];
if (cur == word2.charAt(j - 1)) dp[j] = memo;
else dp[j] = Math.min(Math.min(memo, origin), dp[j - 1]) + 1;
memo = origin;
}
}
return dp[length2];
}
}执行用时3ms,击败99.19%,复杂度O(length1 * length2)
消耗内存43.56MB,击败97.53%,复杂度O(length2)