
一、二叉树的遍历
1.1 深度优先搜索dfs
尽可能“深”地走下去直到不能走为止,然后回溯继续其它分支,实现常用递归或栈(显式模拟递归)。
- 递归容易写,但注意可能会有栈深(树高度)问题;对链状树深度 = n 时递归会导致调用栈溢出。
- 迭代版更稳定(显式栈),但代码有时略复杂(尤其是后序)。
简单
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

输入:root = [1,null,2,3]
输出:[1,3,2]示例 2:
输入:root = []
输出:[]示例 3:
输入:root = [1]
输出:[1]提示:
- 树中节点数目在范围
[0, 100]内 -100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
1.1.1 递归
Node(根)、Left(左)、Right(右)
前序(NLR):根节点——左子树——右子树
中序(LNR):左子树——根节点——右子树
中序(LRN):左子树——右子树——根节点
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
/**
* 94. 二叉树的中序遍历(dfs)
*
* @param root 根节点
* @return 中序遍历结果列表
*/
public List<Integer> inorderTraversal(TreeNo0de root) {
List<Integer> res = new ArrayList<>();
inorder(root, res);
return res;
}
public void inorder(TreeNode root, List<Integer> res) {
if (root == null) return;
inorder(root.left, res);
res.add(root.val);
inorder(root.right, res);
}
}核心迭代步骤:
前序
void preorder(TreeNode root) {
if (root == null) return;
visit(root); // N,访问当前节点
preorder(root.left); // L,访问左子树
preorder(root.right); // R,访问右子树
}中序
void inorder(TreeNode root) {
if (root == null) return;
inorder(root.left); // L
visit(root); // N,即本题的add逻辑
inorder(root.right); // R
}后序
void postorder(TreeNode root) {
if (root == null) return;
postorder(root.left); // L
postorder(root.right); // R
visit(root); // N
}1.1.2 迭代
前序
public List<Integer> preorderIter(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(node.val); // N
if (node.right != null) stack.push(node.right); // 先压右再压左
if (node.left != null) stack.push(node.left);
}
return res;
}中序
public List<Integer> inorderTraversalIter(TreeNode root) {
List<Integer> res = new ArrayList<>();
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
while (cur != null) { // 一直走到最左
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
res.add(cur.val); // 访问
cur = cur.right; // 进入右子树
}
return res;
}后序
// 方法一:两栈法(或用一个栈+上次访问节点标记)
public List<Integer> postorderIter(TreeNode root) {
LinkedList<Integer> res = new LinkedList<>();
if (root == null) return res;
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
res.addFirst(node.val); // 把根先放到结果头部,相当于反序
if (node.left != null) stack.push(node.left);
if (node.right != null) stack.push(node.right);
}
return res; // 已经是后序
}1.2 广度优先搜索bfs
按层级逐层访问,从起点开始,先访问所有距离为 1 的节点,再距离为 2 的,依此类推。通常用队列实现(先入先出)。
- 用队列(Queue),把根入队,循环弹出并把左右子节点入队;若需要按层输出,记录队列当前大小即可。
中等
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]示例 2:
输入:root = [1]
输出:[[1]]示例 3:
输入:root = []
输出:[]提示:
- 树中节点数目在范围
[0, 2000]内 -1000 <= Node.val <= 1000
1.2.1 递归(dfs解法)
在递归时传递当前层级的深度,以此来标识不同层级之间的元素
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
private final List<List<Integer>> res = new ArrayList<>();
/**
* 102. 二叉树的层序遍历(dfs)
*
* @param root 根节点
* @return 层序遍历结果
*/
public List<List<Integer>> levelOrder(TreeNode root) {
dfs(root, 1);
return res;
}
public void dfs(TreeNode root, int level) {
if (root == null) return;
if (res.size() < level) {
res.add(new ArrayList<>());
}
res.get(level - 1).add(root.val);
dfs(root.left, level + 1);
dfs(root.right, level + 1);
}
}1.2.2 迭代(bfs解法)
把根入队,循环每一层时记录当前队列大小 size,然后弹出 size 个节点(这些就是当前层),把它们的值收集到当前层列表,并把它们的左右孩子入队,完成一层后把层列表加入结果。
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) return res;
Deque<TreeNode> q = new ArrayDeque<>();
q.offer(root);
while (!q.isEmpty()) {
int size = q.size();
List<Integer> level = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
TreeNode node = q.poll();
level.add(node.val);
if (node.left != null) q.offer(node.left);
if (node.right != null) q.offer(node.right);
}
res.add(level);
}
return res;
}二、二叉树的最大深度
简单
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:
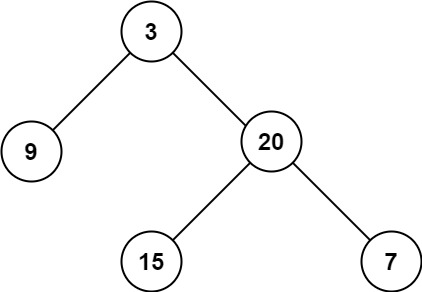
输入:root = [3,9,20,null,null,15,7]
输出:3示例 2:
输入:root = [1,null,2]
输出:2提示:
- 树中节点的数量在
[0, 10^4]区间内。 -100 <= Node.val <= 100
2.1 dfs
即递归遍历时的
visit的逻辑为:维护最大深度
/**
* 104. 二叉树的最大深度(dfs)
*
* @param root 根节点
* @return 最大深度
*/
public int maxDepth(TreeNode root) {
if (root == null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left, right) + 1;
}2.2 bfs
按层处理时方便做其它层级统计(例如每层节点平均值、最大值等)
public int maxDepth(TreeNode root) {
if (root == null) return 0;
Deque<TreeNode> q = new ArrayDeque<>();
q.offer(root);
int depth = 0;
while (!q.isEmpty()) {
int size = q.size();
for (int i = 0; i < size; i++) {
TreeNode node = q.poll();
if (node.left != null) q.offer(node.left);
if (node.right != null) q.offer(node.right);
}
depth++;
}
return depth;
}三、翻转二叉树
简单
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
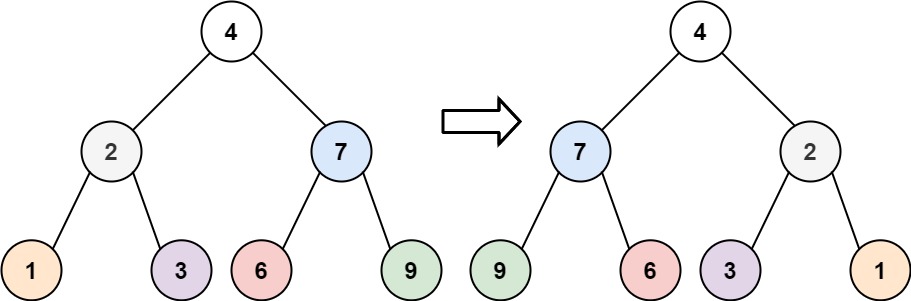
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]示例 2:
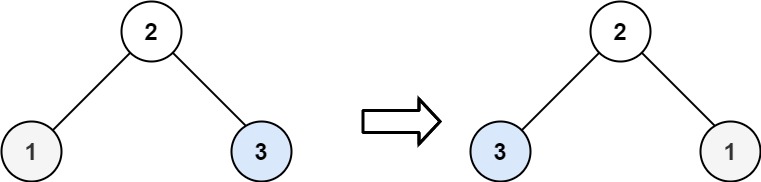
输入:root = [2,1,3]
输出:[2,3,1]示例 3:
输入:root = []
输出:[] 提示:
- 树中节点数目范围在
[0, 100]内 -100 <= Node.val <= 100
3.1 dfs
即递归遍历时的
visit的逻辑为:交换左右子树
/**
* 226. 翻转二叉树(dfs)
*
* @param root 根节点
* @return 翻转后的根节点
*/
public TreeNode invertTree(TreeNode root) {
if (root == null) return null;
// 交换左右子树
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 递归翻转左右子树
invertTree(root.left);
invertTree(root.right);
return root;
}四、对称二叉树
简单
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:
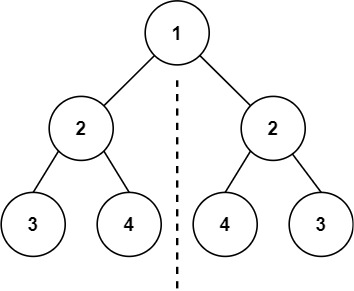
输入:root = [1,2,2,3,4,4,3]
输出:true示例 2:
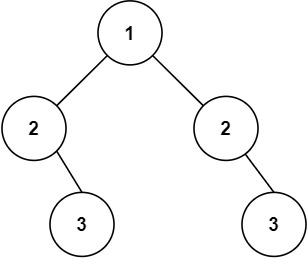
输入:root = [1,2,2,null,3,null,3]
输出:false提示:
- 树中节点数目在范围
[1, 1000]内 -100 <= Node.val <= 100
**进阶:**你可以运用递归和迭代两种方法解决这个问题吗?
4.1 dfs
即递归遍历时的
visit的逻辑为:判断是否为对称节点
/**
* 101. 对称二叉树(dfs)
*
* @param root 根节点
* @return 是否对称
*/
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return isMirror(root.left, root.right);
}
private boolean isMirror(TreeNode a, TreeNode b) {
if (a == null && b == null) return true;
if (a == null || b == null) return false;
if (a.val != b.val) return false;
// 左的左 <-> 右的右, 左的右 <-> 右的左
return isMirror(a.left, b.right) && isMirror(a.right, b.left);
}4.2 bfs
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
Deque<TreeNode> q = new ArrayDeque<>();
// 初始把左右子节点成对放入队列
q.add(root.left);
q.add(root.right);
while (!q.isEmpty()) {
TreeNode a = q.poll();
TreeNode b = q.poll();
if (a == null && b == null) continue;
if (a == null || b == null) return false;
if (a.val != b.val) return false;
// 将下一层需要比较的节点按镜像顺序放入队列
q.add(a.left);
q.add(b.right);
q.add(a.right);
q.add(b.left);
}
return true;
}👆运行报空指针异常, 这是因为ArrayDeque(new ArrayDeque<>())不允许添加 null 元素,调用 add(null) 会抛出 NPE
改为Deque<TreeNode> q = new LinkedList<>();即可
- ArrayDeque:基于动态数组的双端队列(环形缓冲区)。不允许 null 元素。对于做栈(push/pop)或队列(offer/poll)几乎总是最快的选择。对首尾的增删为 O(1)(摊还),遍历速度快,内存占用小(元素连片存储)。
- LinkedList:基于双向链表,既实现了 List 也实现了 Deque。允许 null。对任意位置插入/删除(当已定位到该位置的节点)为 O(1),但随机访问 get(i) 为 O(n)。相比 ArrayDeque 每个元素额外有节点对象开销(更多内存),遍历较慢(指针跳跃)。
❓如何选择
- 优先选择 ArrayDeque:
- 需要一个高性能的栈或队列(LIFO/ FIFO / Deque)
- 不需要存放 null
- 对性能/内存敏感(大多数场景 ArrayDeque 更快、更省内存)
- 选择 LinkedList 的场景:
- 必须允许 null 值(注意大多数队列/栈场景不需要 null)
- 需要把结构既当作 List 又当作 Deque 使用(但通常 ArrayList + ArrayDeque 更合适)
五、二叉树的直径
简单
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
示例 1:
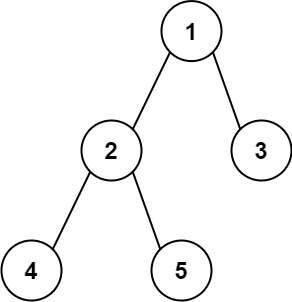
输入:root = [1,2,3,4,5]
输出:3
解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。示例 2:
输入:root = [1,2]
输出:1提示:
- 树中节点数目在范围
[1, 10^4]内 -100 <= Node.val <= 100
5.1 dfs
即递归遍历时的
visit的逻辑为:维护最大路径长度
class Solution {
private int depth = 0;
/**
* 543. 二叉树的直径(dfs)
*
* @param root 根节点
* @return 最长路径长度
*/
public int diameterOfBinaryTree(TreeNode root) {
dfs(root);
return depth;
}
public int dfs(TreeNode root) {
if (root == null) return 0;
int l = dfs(root.left);
int r = dfs(root.right);
depth = Math.max(depth, l + r);
return Math.max(l, r) + 1;
}
}六、将有序数组转换为二叉搜索树
简单
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。
示例 1:
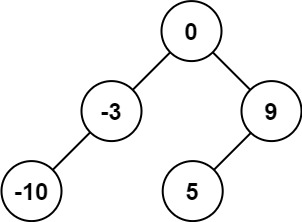
输入:nums = [-10,-3,0,5,9]
输出:[0,-3,9,-10,null,5]
解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:示例 2:
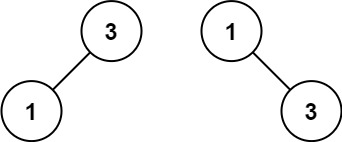
输入:nums = [1,3]
输出:[3,1]
解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。提示:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4nums按 严格递增 顺序排列
6.1 dfs
中序遍历结果是有序数组;
但是二叉搜索树的中序遍历不可以唯一地确定二叉搜索树
要构造高度平衡 BST,可递归地在数组中选择中点作为根,左半区构造左子树、右半区构造右子树。
/**
* 108. 将有序数组转换为二叉搜索树(dfs)
*
* @param nums 升序数组
* @return 构建的二叉搜索树根节点
*/
public TreeNode sortedArrayToBST(int[] nums) {
return build(nums, 0, nums.length - 1);
}
public TreeNode build(int[] nums, int l, int r) {
if (l > r) return null;
int m = (l + r) / 2;
TreeNode root = new TreeNode(nums[m]);
root.left = build(nums, l, m - 1);
root.right = build(nums, m + 1, r);
return root;
}七、验证二叉搜索树
中等
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 严格小于 当前节点的数。
- 节点的右子树只包含 严格大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:

输入:root = [2,1,3]
输出:true示例 2:

输入:root = [5,1,4,null,null,3,6]
输出:false
解释:根节点的值是 5 ,但是右子节点的值是 4 。提示:
- 树中节点数目范围在
[1, 10^4]内 -2^31 <= Node.val <= 2^31 - 1
7.1 dfs
class Solution {
Integer last = null;
/**
* 98. 验证二叉搜索树(dfs)
*
* @param root 根节点
* @return 判断结果
*/
public boolean isValidBST(TreeNode root) {
return inorder(root);
}
public boolean inorder(TreeNode root) {
if (root == null) return true;
if (!inorder(root.left)) return false;
// inorder(左,val1)
if (last != null && last >= root.val) return false;
last = root.val;
return inorder(root.right);
}
}八、二叉搜索树中第 K 小的元素
中等给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(k 从 1 开始计数)。
示例 1:
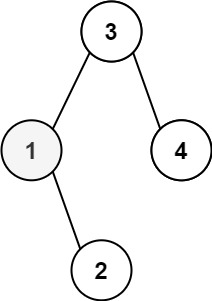
输入:root = [3,1,4,null,2], k = 1
输出:1示例 2:
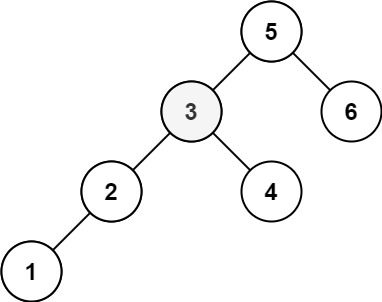
输入:root = [5,3,6,2,4,null,null,1], k = 3
输出:3提示:
- 树中的节点数为
n。 1 <= k <= n <= 1040 <= Node.val <= 104
进阶:
如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?
8.1 dfs
即递归遍历时的
visit的逻辑为:记录当前为第 i 小的元素
class Solution {
int i = 0;
int res;
/**
* 230. 二叉搜索树中第 K 小的元素(dfs)
*
* @param root 根节点
* @param k 排序
* @return 第 K 小的元素
*/
public int kthSmallest(TreeNode root, int k) {
inorder(root, k);
return res;
}
public void inorder(TreeNode root, int k) {
if (root == null) return;
inorder(root.left, k);
i++;
if (i == k) res = root.val;
inorder(root.right, k);
}
}8.2 进阶
有兴趣的可看,手搓avl树目前看起来并不需要牢记
九、二叉树的右视图
中等
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:
输入:root = [1,2,3,null,5,null,4]
输出:[1,3,4]
解释:
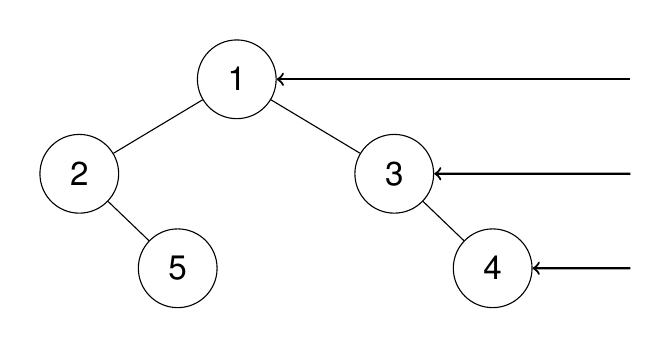
示例 2:
输入:root = [1,2,3,4,null,null,null,5]
输出:[1,3,4,5]
解释:

示例 3:
输入:root = [1,null,3]
输出:[1,3]
示例 4:
输入:root = []
输出:[]
提示:
- 二叉树的节点个数的范围是
[0,100] -100 <= Node.val <= 100
9.1 dfs
👆在本文章中 1.2.1 递归(dfs解法) 中有出现过相同的方法
即:在dfs时额外传入一个level参数来标识当前层级深度
class Solution {
private List<Integer> res = new ArrayList<>();
/**
* 199. 二叉树的右视图(dfs)
*
* @param root 根节点
* @return 右视图元素集合
*/
public List<Integer> rightSideView(TreeNode root) {
dfs(root, 0);
return res;
}
public void dfs(TreeNode root, int level) {
if (root == null) return;
if (level == res.size()) {
res.add(root.val);
}
dfs(root.right, level + 1);
dfs(root.left, level + 1);
}
}9.2 bfs
public List<Integer> rightSideView(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Queue<TreeNode> q = new ArrayDeque<>();
q.offer(root);
while (!q.isEmpty()) {
int size = q.size();
for (int i = 0; i < size; i++) {
TreeNode node = q.poll();
// i == size-1 表示本层的最后一个节点(最右)
if (i == size - 1) res.add(node.val);
if (node.left != null) q.offer(node.left);
if (node.right != null) q.offer(node.right);
}
}
return res;
}十、二叉树展开为链表
中等
提示
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历↗ 顺序相同。
示例 1:
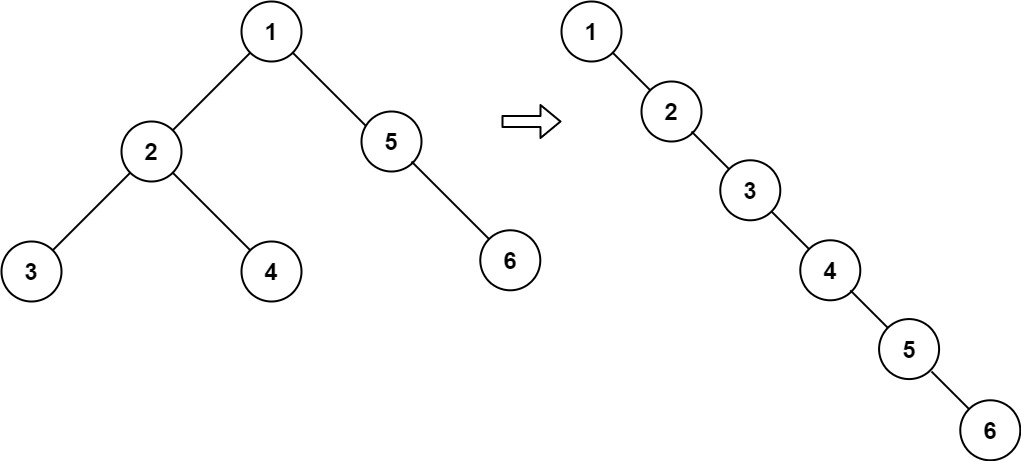
输入:root = [1,2,5,3,4,null,6]
输出:[1,null,2,null,3,null,4,null,5,null,6]示例 2:
输入:root = []
输出:[]示例 3:
输入:root = [0]
输出:[0]提示:
- 树中结点数在范围
[0, 2000]内 -100 <= Node.val <= 100
进阶:你可以使用原地算法(O(1) 额外空间)展开这棵树吗?
10.1 dfs
class Solution {
/**
* 114. 二叉树展开为链表(dfs)
*
* @param root 根节点
*/
public void flatten(TreeNode root) {
if (root == null) return;
flatten(root.left);
flatten(root.right);
// 若存在左子树,则将左子树插到右子树位置,并把原右子树接到左子树的尾部
if (root.left != null) {
TreeNode l = root.left;
TreeNode r = root.right;
root.right = l;
root.left = null;
// 找到新的右子树(原左子树)的尾节点
TreeNode tail = l;
while (tail.right != null) tail = tail.right;
// 把原右子树接回
tail.right = r;
}
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存43.04MB,击败45.25%,复杂度O(H)
10.2 dfs图解
- 初始状态
1
/ \
2 5
/ \ / \
3 4 6 7- 不断递归左子树,到达节点
3 - 再次递归左子树、右子树,均为
null,执行到if (root.left != null)语句,为false - 步骤3是节点
2的flatten(root.left);,已经执行完毕,同理,节点2的flatten(root.right);也不会进行操作 - 执行到节点
2的if (root.left != null)语句,为true
- 取下左右子树,把左子树接在节点
2的右子树上,节点2的左子树悬空
1
/ \
2 5
4 \ / \
====> 3 6 7- 从节点
2的右子树节点3开始,不断递归右子树,找到末尾节点tail - 这里刚好节点
3就是末尾节点,把取下来的4接回末尾节点的右子树
1
/ \
2 5
\ / \
3 6 7
\
====> 4- 节点
2执行完毕,即节点1的flatten(root.left);执行完毕,进入节点1的flatten(root.right); - 同理,执行完后,树状如下
1
/ \
2 5
\ \
3 6
\ \
4 7- 节点
1的flatten(root.right);执行完毕,执行到节点1的if (root.left != null)语句,为true
- 取下左右子树,把左子树接在节点
1的右子树上,节点1的左子树悬空
1
5 \
\ 2
6 \
\ 3
7 \
====> 4- 从节点
1的右子树节点2开始,不断递归右子树,找到末尾节点tail,即节点4 - 把取下来的
5 - 6 - 7接回末尾节点的右子树,得到答案
1
\
2
\
3
\
4
\
5
\
6
\
7 10.3 Morris(空间复杂度O(1))
public void flatten(TreeNode root) {
TreeNode cur = root;
while (cur != null) {
if (cur.left != null) {
TreeNode pred = cur.left;
// 找左子树最右节点
while (pred.right != null) pred = pred.right;
// 接回原右子树
pred.right = cur.right;
// 把左子树移到右侧
cur.right = cur.left;
cur.left = null;
}
cur = cur.right;
}
}执行用时0ms,击败100.00%,复杂度O(N)
消耗内存43.29MB,击败22.31%,复杂度O(1)
10.4 Morris图解
1
/ \
2 5
/ \ / \
3 4 6 7cur = 1(cur.left != null)
把节点2和节点5从节点1取下来
- pred = cur.left = 2;寻找最右:pred -> 4(2.right=4,4.right == null,所以 pred = 4)
- 执行操作:
- pred.right = cur.right // 4.right = 5
- cur.right = cur.left // 1.right = 2
- cur.left = null // 1.left = null
- 移动:cur = cur.right(cur = 2)
- 树状态(after Step 1):
1
\
2
/ \
3 4
\
5
/ \
6 7cur = 2(cur.left != null)
- pred = cur.left = 3;寻找最右:pred = 3(3.right == null)
- 执行操作:
- pred.right = cur.right // 3.right = 4
- cur.right = cur.left // 2.right = 3
- cur.left = null // 2.left = null
- 移动:cur = cur.right(cur = 3)
- 树状态(after Step 2):
1
\
2
\
3
\
4
\
5
/ \
6 7cur = 3(cur.left == null)
- 直接 cur = cur.right → cur = 4
- 树结构不变(3.left = null,3.right = 4)。
…
同理,最后得到答案
十一、从前序与中序遍历序列构造二叉树
中等
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列
11.1 dfs
❓本题中提示,
preorder和inorder均 无重复 元素,是否有什么特殊的深意
注意到,前序遍历 preorder 数组的前几个元素,从根节点下来一直是左子树,如果没有重复元素,当
preorder[preIndex] == inorder[0]时候,说明左子树已经构建完成了每个值在 inorder 中唯一出现,preorder 中取出的根值能唯一确定它在中序中的分割位置,才能用“值比较”作为边界判断
- 维护两个指针:
- preIndex(遍历 preorder,表示下一个要建的节点)
- inIndex(遍历 inorder,表示下一个在中序上要“消费”的节点)
inorder[inIndex]总是当前未被“消费”的最左侧节点(即中序扫描的下一个节点)。- 若在构造某个子树时遇到
preorder[preIndex] == inorder[inIndex]- 说明下一个要创建的节点恰好是中序上当前的位置
- 当前递归层的左子树结束
- 回到父节点去构建右子树
public class Solution {
private int preIndex = 0, inIndex = 0;
private int[] preorder, inorder;
/**
* 105. 从前序与中序遍历序列构造二叉树(dfs)
*
* @param preorder 前序遍历数组
* @param inorder 中序遍历数组
* @return 构建的树的根节点
*/
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
this.inorder = inorder;
preIndex = 0;
inIndex = 0;
return build(null);
}
private TreeNode build(Integer stop) {
if (preIndex >= preorder.length) return null;
// 如果当前 inorder 值等于 stop,说明当前子树结束(跳过 stop 并返回 null)
if (stop != null && inIndex < inorder.length && inorder[inIndex] == stop) {
inIndex++; // 越过终止值
return null;
}
// 从 preorder 取当前根并构造
int rootVal = preorder[preIndex++];
TreeNode root = new TreeNode(rootVal);
// 左子树在中序中以 rootVal 为终止点
root.left = build(rootVal);
// 构造右子树,右子树终止点继承父层的 stop
root.right = build(stop);
return root;
}
}执行用时1ms,击败99.52%,复杂度O(N)
消耗内存44.63MB,击败50.84%,复杂度O(N)
11.2 dfs图解
初始
preorder = [3, 9, 20, 15, 7] preIndex = 0
inorder = [9, 3, 15, 20, 7] inIndex = 0
调用: build(stop = null)- 构造根节点(build(null))
preorder[preIndex]=3→ 创建节点 3,preIndex-> 1- 接着构造 3 的左子树:调用
build(stop = 3)
3
/ \
? ?
(preIndex=1, inIndex=0) 2.1构造 3 的左子树(build(3))
preorder[1]=9→ 创建节点 9,preIndex-> 2- 构造 9 的左:调用
build(stop = 9)
2.2 build(9)
- 检查
inorder[inIndex] == stop ? inorder[0] == 9 == stop-> 成立 inIndex++; // 越过终止值-> 1,返回 null(表示 9.left = null)
2.3 回到 9,构造 9 的右:调用 build(stop = 3)
- 检查
inorder[inIndex] == stop ? inorder[1] == 3 == stop-> 成立 inIndex++; // 越过终止值-> 2,返回 null(表示 9.right = null)
3
/ \
9 ?
(preIndex=2, inIndex=2)- 回到根 3,开始构造 3 的右子树:调用 build(stop = null)
preorder[2]=20→ 创建节点 20,preIndex-> 3
3
/ \
9 20
(preIndex=3, inIndex=2) 4.1 构造 20 的左子树:调用 build(stop = 20)
preorder[3]=15→ 创建节点 15,preIndex-> 4
4.2 构造 15 的左:调用 build(stop = 15)
- 检查
inorder[inIndex] == stop ? inorder[2] == 15 == stop-> 成立 inIndex++; // 越过终止值-> 3,返回 null(15.left = null)
4.3 构造 15 的右:调用 build(stop = 20)
- 检查 inorder[inIndex] == stop ? inorder[3] == 20 == stop -> 成立
inIndex++; // 越过终止值-> 4,返回 null(15.right = null)
3
/ \
9 20
/
15
(preIndex=4, inIndex=4) 5.1 构造 20 的右子树:调用 build(stop = null)
preorder[4]=7→ 创建节点 7,preIndex-> 55.2 构造 7 的左:调用 build(stop = 7)
检查
inorder[inIndex] == stop ? inorder[4] == 7 == stop-> 成立inIndex-> 5,返回 null(7.left = null)5.3 构造 7 的右:调用 build(stop = null)
preIndex == preorder.length(5),返回 null(7.right = null)
3
/ \
9 20
/ \
15 7
(preIndex=5, inIndex=5)再来看一棵树的终止序列
1 阿拉伯数字:树的val
一/ \空
2 9 中文数字:递归过程传递的stop值的中文
二/ \一 / \空 比如stop=1,标注“一”
3 6 10 13 比如stop=null,标注“空”
三/ \二 / \一 / \ \空
4 5 7 8 11 12
四/ \三 \二- preorder = [1,2,3,4,5,6,7,8,9,10,11,12,13]
- inorder = [4,3,5,2,7,6,8,1,11,10,12,9,13]
因为右子树的stop始终是父节点的val
- 所以值为2、6、8的节点的终止值均为2的父亲1
- 值为1、9、13的节点的终止值均为1的父亲null
走到4-四,触发inorder[inIndex] == stop,即inorder[0] == 四,index从0变成1
紧接着进入4-三,又触发inorder[inIndex] == stop,即inorder[1] == 三,index从1变成2
上边为3-三,接下来进入3-二
进入5的左子树(图中未标注,即5-五),触发inorder[inIndex] == stop,即inorder[2] == 五,index从2变成3
紧接着进入5-二,又触发inorder[inIndex] == stop,即inorder[3] == 二,index从3变成4
…
同理可得,树构建完毕
十二、路径总和 III
中等
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
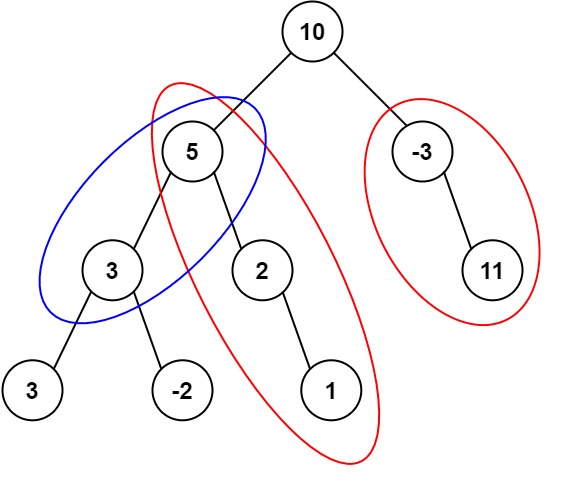
输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
输出:3
解释:和等于 8 的路径有 3 条,如图所示。示例 2:
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:3提示:
- 二叉树的节点个数的范围是
[0,1000] -10^9 <= Node.val <= 10^9-1000 <= targetSum <= 1000
12.1 dfs
老演员了,这种悬空连续数组,请出伟大的前缀和
∵ currSum - oldSum = target
∴ prefix = oldSum = currSum - target
❓为什么要Long类型的键,不能用Integer吗
用Integer会发现有一个测试用例通过不了,因为sum超出int范围了
❓为什么不分两步走:先走完所有路径把所有值都存入map,再求解
- 一来步骤重复,而且时间复杂度最坏会变为
O(n^3) - 二来结果可能会偏大,因为有可能
左边的前缀和 - 右边的前缀和 = targetSum
5
/ \
3 8
/ \ / \
1 4 7 10
/ \
2 12如👆,targetSum = 14,5 + 3 + 1 = 9,5 + 8 + 10 = 23
发现23 - 9 = targetSum,于是ans++,但是根本没有这条路可以走
/**
* 437. 路径总和 III(dfs)
*
* @param root 根节点
* @param targetSum 目标和
* @return 路径总数
*/
public int pathSum(TreeNode root, int targetSum) {
Map<Long, Integer> prefix = new HashMap<>();
prefix.put(0L, 1);
return dfs(root, 0L, targetSum, prefix);
}
private int dfs(TreeNode node, long currSum, int target, Map<Long, Integer> prefix) {
if (node == null) return 0;
currSum += node.val;
int res = prefix.getOrDefault(currSum - target, 0);
prefix.put(currSum, prefix.getOrDefault(currSum, 0) + 1);
res += dfs(node.left, currSum, target, prefix);
res += dfs(node.right, currSum, target, prefix);
prefix.put(currSum, prefix.get(currSum) - 1);
return res;
}执行用时3ms,击败99.99%,复杂度O(N)
消耗内存45.67MB,击败14.67%,复杂度O(N)
十三、二叉树的最近公共祖先
中等
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科↗中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:

输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。示例 2:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。示例 3:
输入:root = [1,2], p = 1, q = 2
输出:1提示:
- 树中节点数目在范围
[2, 105]内。 -10^9 <= Node.val <= 10^9- 所有
Node.val互不相同。 p != qp和q均存在于给定的二叉树中。
13.1 暴力起手(dfs+回溯)
先分别找到从根节点到 p、q 的路径 pathP、pathQ
然后正序遍历,直到
pathP.get(i) != pathQ.get(i)
❓不管采用哪种遍历方式,总是会把多余的节点加入到path中去,如何解决
- 把多余的节点移除掉
❓在找到path后如何结束后续递归
- 用返回布尔值控制,找到之后返回
true,在递归之前判断,掐去后续递归
👆其实是一种策略(回溯算法),相关题目见 算法 - 状态(2)↗
/**
* 236. 二叉树的最近公共祖先(暴力)
*
* @param root 根节点
* @param p 节点p
* @param q 节点q
* @return 最近公共祖先节点
*/
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
List<TreeNode> pathP = new ArrayList<>();
List<TreeNode> pathQ = new ArrayList<>();
findPath(root, p, pathP);
findPath(root, q, pathQ);
TreeNode ans = null;
int i = 0;
while (i < pathP.size() && i < pathQ.size()
&& pathP.get(i) == pathQ.get(i)) {
ans = pathP.get(i);
i++;
}
return ans;
}
private boolean findPath(TreeNode node, TreeNode target, List<TreeNode> path) {
if (node == null) return false;
path.add(node);
if (node == target) return true;
if (findPath(node.left, target, path)) return true;
if (findPath(node.right, target, path)) return true;
path.removeLast();
return false;
}执行用时8ms,击败34.51%,复杂度O(N)
消耗内存45.70MB,击败29.54,复杂度O(N)
13.2 优化版dfs
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) return root;
// 在左子树中找 p 或 q
TreeNode left = lowestCommonAncestor(root.left, p, q);
// 在右子树中找 p 或 q
TreeNode right = lowestCommonAncestor(root.right, p, q);
// 左右都找到,则当前 root 就是最近公共祖先
if (left != null && right != null) return root;
// 只找到一个,则把那个往上返回
return left != null ? left : right;
}执行用时8ms,击败34.51%,复杂度O(N)
消耗内存45.75MB,击败18.49%,复杂度O(H)
十四、二叉树中的最大路径和
困难
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
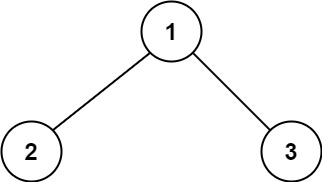
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6示例 2:
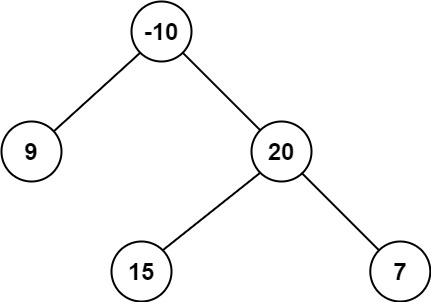
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42提示:
- 树中节点数目范围是
[1, 3 * 10^4] -1000 <= Node.val <= 1000
14.1 dfs
👆回看本文章的 第五题(二叉树的直径) ,再回看这道题
class Solution {
private int depth = 0;
/**
* 543. 二叉树的直径(dfs)
*
* @param root 根节点
* @return 最长路径长度
*/
public int diameterOfBinaryTree(TreeNode root) {
dfs(root);
return depth;
}
public int dfs(TreeNode root) {
if (root == null) return 0;
int l = dfs(root.left);
int r = dfs(root.right);
depth = Math.max(depth, l + r);
return Math.max(l, r) + 1; // 在此处,+1 表示节点计数+1
}
}对于本题,我们要求的是路径,把+1改成root.val即可
需要注意,节点不是一定要经过的(因为从该节点扩散出去的路径和,迭代回来结果 < 0,没必要计算进去)
class Solution {
private int path = Integer.MIN_VALUE;
/**
* 124. 二叉树中的最大路径和
*
* @param root 根节点
* @return 最大路径和
*/
public int maxPathSum(TreeNode root) {
dfs(root);
return path;
}
public int dfs(TreeNode root) {
if (root == null) return 0;
int l = Math.max(0, dfs(root.left)); // 迭代结果<0说明左分支不考虑
int r = Math.max(0, dfs(root.right)); // 迭代结果<0说明右分支不考虑
path = Math.max(path, l + r + root.val);
return Math.max(l, r) + root.val;
}
}执行用时1ms,击败84.14%,复杂度O(N)
消耗内存46.03MB,击败8.73%,复杂度O(H)